Replication
- Replication: Keeping a copy of same data
- why replication ?
- to keep data geographically close to users -> reduce latency
- To allow system to continue working even if some parts have failed -> High availability
- Increase read throughput
- Easy Part: Data does not change over time
- copy data to every node once and you are done
- Hard Part: Handling changes to replicated data (Point of Discussion in this chapter)
- Algorithms of replicating changes between nodes
- single leader replication
- multi leader replication
- leaderless replication
- Trade-offs to consider
- synchronous or asynchronous replication
- How to handle failed replicas
Leader Based Replication
- One replica is designated leader (master or primary)
- client writes to the master then the changes are send to replicas as replication log, each follower takes the logs and updates its local copy of the database by applying all the writes in the same order as they were as they were processed on the leader
- Writes only go through leader, reads can go to any replicas
Synchronous Versus asynchronous Replication
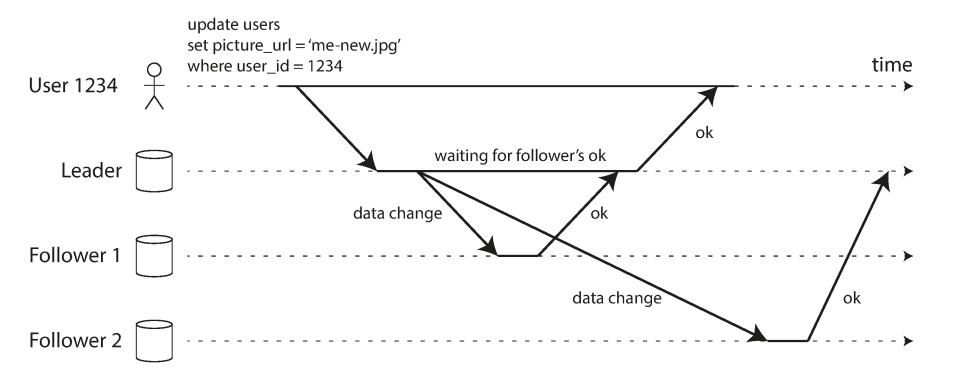 Leader Based replication across one synchronous and one asychronous follower
Leader Based replication across one synchronous and one asychronous follower- Replication to follower 1 -> synchronous
- Leader waits until follower 1 confirms it has received the writes before reporting success to user
- Replication to follower 2 -> asynchronous
- the leader sends the message, but doesn’t wait for a response from the follower
- Normally replication is quite fast but scenarios may arise where followers might fall behind followers by several minutes
- Network failures
- Recovering from failures
- System operating at maximum capacity
- Advantages of Synchronous Replication
- follower is guaranteed to have an up-to-date copy of the data that is consistent with the leader
- Disadvantages of Synchronous Replication
- If the Synchronous follower doesn’t respond the leader has to block all writes until Synchronous replica is available again
- it is impractical for all followers to be synchronous: any one node outage would cause the whole system to grind to a halt
- semi-synchronous: one of the followers is synchronous, and the others are asynchronous
- if synchronous becomes unavailable, asynchronous is made sync and this guarantees we always have copies of data on at least 2 nodes.
- Durability guarantees in async replication
- If the leader fails and writes have not been replicated to followers, the write is lost
- But a full async replication has the advantage that the leader can continue processing data even if all of its followers have fallen behind.
- Here the trade-off is weakening of durability, nevertheless fully async replication is widely used if there are many followers that are geographically distributed
- chain replication is a variant of synchronous replication that has been successfully implemented in a few systems such as Microsoft Azure Storage
Setting up new followers
- you may need to increase the number of replicas or replace failed node, how to ensure that the new node has updated data
- How to do it ?
- Take a consistent snapshot leader’s database at some point in time
- Copy the snapshot to the new follower node
- connects to the leader and requests all the data changes that have happened since the snapshot was taken
- log sequence number(PostgreSQL)/binlog coordinates(MySQL)
- the snapshot is associated with an exact position in the leader’s replication log
- log sequence number(PostgreSQL)/binlog coordinates(MySQL)
- Once follower has processed the backlog of data changes since the snapshot,we say it has caught up
Handling Node Outages
- How do you achieve high availability with leader-based replication?
Follower failure: Catch-up recovery
- each follower keeps a log of the data changes
- If a follower crashes and is restarted, it knows the last transaction that was processed before the fault occurred, thus it can connect to the leader and request all the data changes that occurred during the time when the follower was disconnected
Leader failure: Failover
- Handling leader failure is trickier
- Failover Process
- One follower needs to be made leader
- clients need to be configured to send writes to new leader
- Other followers starts to start consuming from the leader
- Automatic Failover Process
- How to determine a leader has failed: if the node doesn’t respond for some period of time it is assumed to be dead
- Choosing a new leader: Agreeing on a new leader is a consensus problem, This is done through an election process
- Reconfiguring the system to use the new leader: Clients need to send the write request to the new leader. If old leader comes back it may think it is the leader, the system needs to ensure that old leader becomes a follower and steps down
- Things that can go wrong in automatic failover
- If new leader doesn’t have all the writes from the old leader
- if a former leader rejoins the cluster after a new leader has been chosen the new leader may have received conflicting writes
- A solution to this is to discard writes of old leader, this may violate clients durability expectations
- Github Incident
- Out of date MySQL follower was promoted to leader, database used an auto incrementing counter to assign primary keys to new rows, but old leader counter lagged behind the old leaders, it reused some primary keys that was assigned in old leader, these primary keys were used in a redis store which caused some private data to be disclosed to wrong users
- split brain: two nodes both believe that they are the leader
- if both leaders accept writes, and there is no process for resolving conflicts
- Time out periods: longer timeout means longer recovery time, if timeout is too short there could be unnecessary failovers.
Implementation of Replication Logs
Statement-based replication
- Every write request is sent to the followers (every INSERT, UPDATE, or DELETE statement is forwarded to followers)
- issues with the approach
- Nondeterministic function is called such as NOW() or RAND()
- if the statements use autoincrementing column or they depend on existing data (UPDATE WHERE) they need to be applied in same order or else they may have a different effect
- Statements that have side effects (e.g., triggers, stored procedures, user-defined functions)
- Workaround
- leader can replace any nondeterministic function calls with a fixed return value when the statement is logged so that the followers all get the same value
- Too many edge cases so other replication methods are preferred
Write-ahead log (WAL) shipping
- the log is an append-only sequence of bytes containing all writes to the database
- besides writing the log to disk, the leader also sends it across the network to its followers
- This method of replication is used in PostgreSQL and Oracle
- Disadvantage
- a WAL contains details of which bytes were changed in which disk blocks (log describes the data on a very low level)
- This makes replication closely coupled to the storage engine
- If the database changes its storage format from one version to another, it is typically not possible to run different versions of the database software on the leader and the followers
- If the replication protocol allows the follower to use a newer software version than the leader, you can perform a zero-downtime upgrade of the database software
Logical (row-based) log replication
- logical log: use different log format
- separate log formats for replication and storage engines
- A logical log is a sequence of records describing writes to database tables at granularity of rows
- A logical log is decoupled from storage engine internals
- logical log: use different log format
Trigger Based Replication
- More flexibility needed
- only replicate a subset of the data
- replicate from one kind of database to another
- A trigger lets you register custom application code that is automatically executed when a data change (write transaction) occurs
- The trigger has the opportunity to log this change into a separate table, from which it can be read by an external process
- More flexibility needed
Problems with Replication Lag
- if application reads from asynchronous follower, we may see outdated information if the follower has fallen behind, This leads to inconsistencies in the database
- Eventual Consistency: If we run same query on leader and follower at the same time we may get different results, this is a temporary state, if we stop writing to the database eventually all followers will catch up.
- Problems that are likely to occur due to replication lags
Read your own writes
- Suppose a user might write some data like comments and then immediately read it. The write goes to the master whereas read goes to the follower. This may create an issue in asynchronous replication when data may not have reached the replica
- read-after-write consistency/read-your-writes consistency
- This is a guarantee that if a user reloads a page, they will always see any update they submitted
- Read after write consistency in Leader based replication
- when reading something the user has modified read it from the leader otherwise from follower. Detail like user profile information
- If a lot of editable content is there last approach won’t work. Can keep track of last time of update and for one minute after last update, make all reads from leader
- client can keep track of its most recent writes, then the system can ensure that the replica serving any reads for that user reflects updates atleast until that timestamp, if replica is not sufficiently updated the query can wait until replica is updated. The timestamp could be a logical timestamp
Monotonic Reads
- possible for a user to see things moving backward in time.
- if the same query is made twice, each going to a different follower and one having a greater lag then the user may see data disappear
- monotonic reads is a guarantee that the above anomaly doesn’t occur
- One way to ensure this is to make sure that each user always makes their reads from the same replica
Consistent Prefix Reads
- that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order
- This problem is seen in sharded databases
- One solution is to make sure that any writes that are causally related to each other are written to the same partition
Solutions for Replication Lag
- What to do if the replication lag increases to minutes or hours
- There are ways to deal with these issue at the application level, but it is complex and easy to get wrong
- It would be better if application developers don’t have to worry about subtle replication issues
- Transactions exists to address these issues. Single node transactions exists for a long time but in a move to (replicated and sharded) databases many systems have abandoned them claiming they are too expensive in terms of performance and asserting eventual consistency is inevitable in distributed systems. There is some truth in that statement, but it is overly simplistic
Multi-Leader Replication
- Single Leader-based replication has one major downside
- If you can’t connect to the leader for any reason, you can’t write to the database
- allow more than one node to accept writes
- A natural extension of the leader-based replication model is to allow more than one node to accept writes
Use Cases for Multi-Leader Replication
Multi-datacenter operation
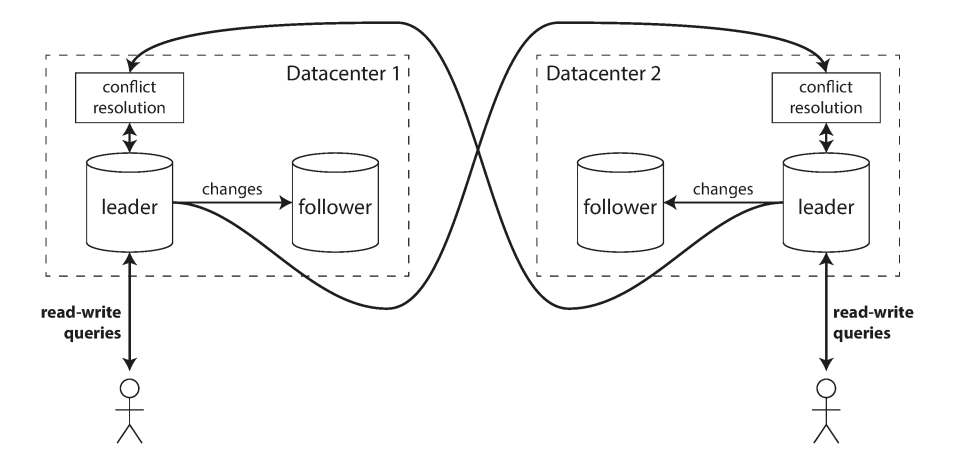 Multileader replication across multiple datacenters
Multileader replication across multiple datacenters- Have a leader in each datacenter and within each datacenter regular leader follower replication is used
- Between datacenter, each datacenter leader replicates its changes to leaders in other datacenters
- Performance:
- In single leader every write must go to the datacenter with the leader, this adds significant latency to the writes, in multileader configuration, every write can be processed in a local datacenter
- Performance:
- Tolerance of datacenter outages
- Tolerance of network problems
- A multi-leader configuration with asynchronous replication can usually tolerate network problems better: a temporary network interruption does not prevent writes being processed
- Assumption is that writes can be processed by other datacenter when one datacenter fails
- some issues with multileader replication
- same data may be concurrently modified in two different datacenters, and those write conflicts must be resolved
- subtle configuration pitfalls, surprising interactions with other database features. For example, autoincrementing keys, triggers, and integrity constraints can be problematic.
- Authors advise
- multi-leader replication is often considered dangerous territory that should be avoided if possible
Clients with offline operation
- if you have an application that needs to continue to work while it is disconnected from the internet
- example: the calendar apps on your mobile phone, your laptop
- Any changes made in any device needs to be synced with server and other devices regardless the device has internet connection or not
- Every device has a local database, that acts as a leader (accepts write requests). There is an asynchronous multi-leader replication process (sync) between the replicas of your calendar on all of your devices.
- each device is a “datacenter” here
- CouchDB is designed for this mode of operation (check out couchdb operation)
Collaborative editing
- Google Docs allow multiple people to concurrently edit a text document or spreadsheet
- When one user edits a document, the changes are instantly applied to their local replica, and asynchronously replicated to the server and any other users who are editing the same document
- This requires conflict resolution
- Single Leader-based replication has one major downside
Handling Write Conflicts
- dealing with conflict resolution
- e.g. a wiki page being modified by 2 users, each user change is successfully applied to their local leader, however when changes are asynchronously replicated a conflict is detected
Synchronous versus asynchronous conflict detection
- In single leader database the writes are blocked until one transaction is complete whereas in a multileader setup writes both writes are successful and conflict is only detected asynchronously
- can make conflict detection synchronous but by doing so, you would lose the main advantage of multi-leader replication: allowing each replica to accept writes independently
Converging toward a consistent state
- A single leader database writes data in sequential order, if there are several updates to the same field, the last writes determines the final value
- every replication scheme must ensure that the data is eventually the same in all replicas. all replicas must arrive at the same final value when all changes have been replicated
- last write wins (LWW): pick the write with the highest timestamp as the winner, and throw away the other writes. This approach is prone to dataloss
- writes that originated at a higher-numbered replica always take precedence This approach also implies data loss
- Avoiding data loss
- merge the two values
- Record the conflict in an explicit data structure and ask the user to resolve the conflict at application code level
Custom conflict resolution logic
- custom conflict resolution at application level. The code may be executed on write or read
- conflict resolution usually applies at the level of an individual row or document, not for an entire transaction
- a transaction that atomically makes several different writes, each write is still considered separately for the purposes of conflict resolution.
Automatic Conflict Resolution
- Conflict-free replicated datatypes
- a family of data structures for sets, maps, ordered lists, counters, etc. that can be concurrently edited by multiple users
- Mergeable persistent data structures
- track history explicitly, similarly to the Git version control system, and use a three-way merge function
- Operational transformation
- Conflict resolution algorithm behind collaborative editing applications such as Etherpad and Google Docs
- Conflict-free replicated datatypes
What is a conflict
- Consider a meeting room booking system
- it tracks which room is booked by which group of people at which time.
- there must not be any overlapping bookings for the same room
- a conflict may arise if two different bookings are created for the same room at the same time (two bookings are made on two different leaders)
- Consider a meeting room booking system
- dealing with conflict resolution
Multi-Leader Replication Topologies
- A replication topology describes the communication paths along which writes are propagated from one node to another
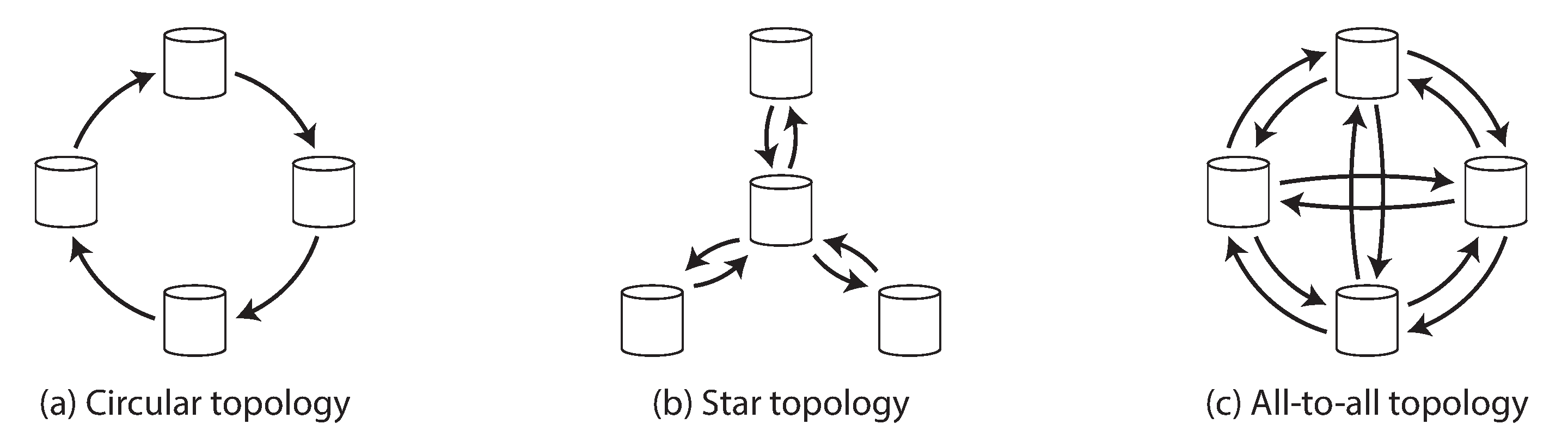 Three example topologies in which multi-leader replication can be set up
Three example topologies in which multi-leader replication can be set up- In circular and star topologies, a write may need to pass through several nodes before it reaches all replicas,Therefore, nodes need to forward data changes they receive from other nodes.
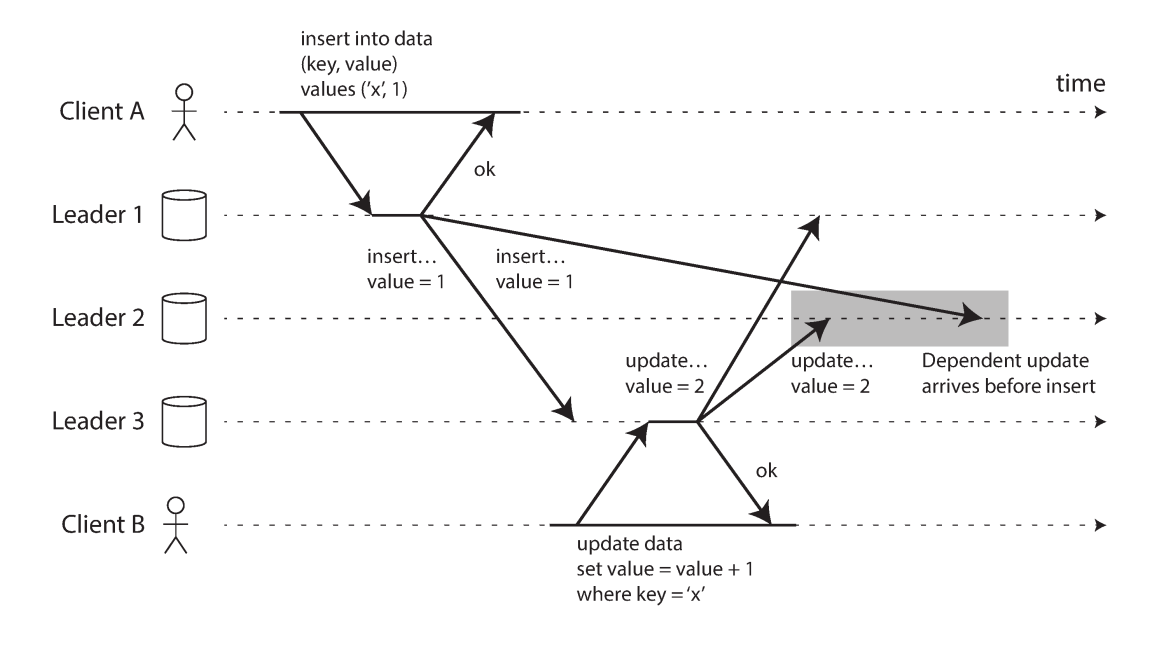 With multi-leader replication, writes may arrive in the wrong order at some replicas.png
With multi-leader replication, writes may arrive in the wrong order at some replicas.png- This is a problem of causality
- To order these events correctly, a technique called version vectors is used
Leaderless Replication
- In single leader or multi-leader approaches, client sends the write to leader and the database system takes care of sending the writes to replicas
- Some storage system don’t have the concept of a leader, any replica can directly accept clients
- Amazon’s dynamo db has leader less replication model
- Cassandra and Voldemort are similar to amazon dynamo
- In some leaderless replication client directly sends writes to different replicas whereas in other a coordinator node is present who sends writes on behalf of the client. The coordinator node in no way enforces ordering of writes
Writing to the Database When a Node Is Down
- In leaderless replication failover doesn’t exist
- If there are 3 replicas, client send the write to all the 3 replicas and if it receives OK responses from 2 replicas it considers it as a successful write and simply ignores the write to missed replica
- If the unavailable node comes back online, and a read operation goes to it, will have stale data
- To solve this problem read requests are also sent to several nodes in parallel, we may get up-to-date value from one node and stale value from other, version numbers are used to determine which value is newer
Read repair and anti-entropy
- After an unavailable node comes back online, how does it catch up on the writes that it missed ?
- Read repair
- when a client gets a stale value from a replica it can write back the updated value but this only works for values that are frequently read
- Anti-entropy process
- Background process that constantly looks for differences in data between replicas and copies any missing data
- Unlike replication log, writes are not copied in any particular order
- Read repair
- After an unavailable node comes back online, how does it catch up on the writes that it missed ?
Quorums for reading and writing
- if we have n replicas, every write must be confirmed by w nodes to be considered successful we must query at least r nodes for each read such that r + w > n. As long as we satisfy this we get up-to-date values when reading
- Reads and writes that obey these r and w values are called quorum reads and writes
- the parameters n, w, and r are typically configurable
- A common choice is to make n an odd number (typically 3 or 5) and to set w = r = (n + 1) / 2 (rounded up)
- We can vary the numbers depending upon the kind of load we see
- a workload with few writes and many reads may benefit from setting w = n and r = 1. This makes reads faster, but has the disadvantage that just one failed node causes all database writes to fail
- reads and writes are always sent to all n replicas in parallel. The parameters w and r determine how many nodes we wait for to report the read or write to be successful
Limitations of Quorum Consistency
- although quorums appear to guarantee that a read returns the latest written value, in practice it is not so simple
- the parameters w and r allow you to adjust the probability of stale values being read, but it’s wise to not take them as absolute guarantees
- In particular,you do not get the guarantees like reading your writes, monotonic reads, or consistent prefix reads
- stronger guarantees generally require transactions or consensus.
Sloppy Quorums and Hinted Handoff
- A network interruption can easily cut off a client from a large number of database nodes
- Though the nodes may be available and other clients can connect for that client the nodes are as good as dead. In this case fewer than w or r reachable nodes remain and the clients can not reach quorum
- In a large cluster (with significantly more than n nodes) it’s likely that the client can connect to some database nodes during the network interruption (the data we are want to read or write resides on n nodes)
- sloppy quorum: if we accepts writes anyway and write them to some nodes that are reachable but not the n nodes on which the value usually resides it is called a sloppy quorum
- writes and reads still require w and r successful responses but those nodes are not the designated nodes for a value
- hinted handoff: Once the network interruption is fixed any writes that one node temporarily accepted on behalf of another node are sent to the appropriate “home” nodes
- Sloppy quorums are particularly useful for increasing write availability: as long as any w nodes are available, the database can accept writes.
Multi-datacenter operation
- the number of replicas n includes nodes in all datacenters, we can specify how many nodes we want per data center
- Each write from a client is sent to all replicas, regardless of datacenter, but the client usually waits for acknowledgement from a quorum of nodes within its local data center
- The higher-latency writes to other datacenters are often configured to happen asynchronously
Detecting Concurrent Writes
- Dynamo style database allows clients to write concurrently to same key. Which means conflict will occur when using strict quorums
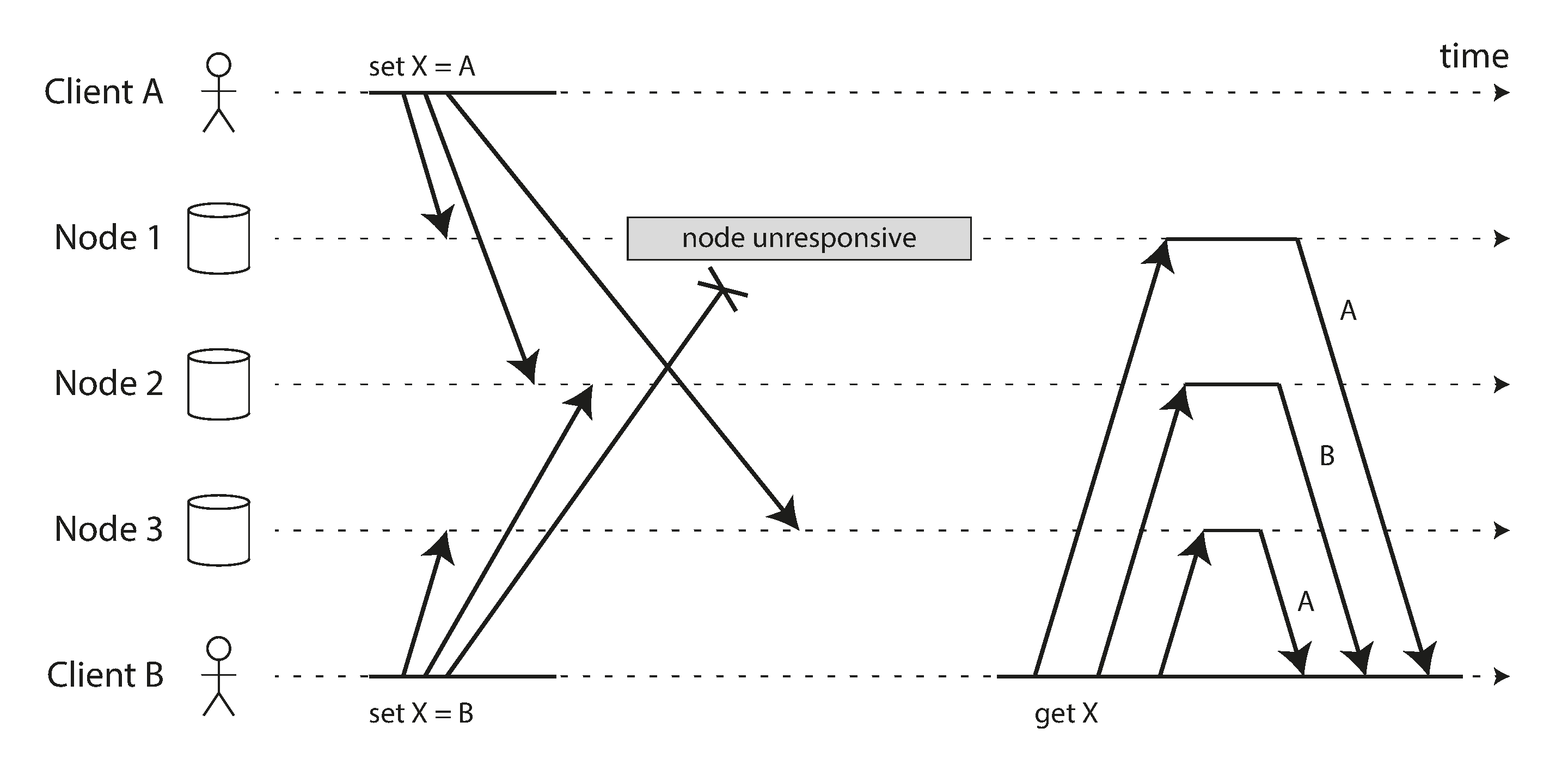 Concurrent writes in a Dynamo-style datastore there is no well-defined ordering
Concurrent writes in a Dynamo-style datastore there is no well-defined ordering- If each node simply overwrote the value for a key whenever it received a write request from a client, the nodes would become permanently inconsistent
Last write wins (discarding concurrent writes)
- each replica need only store the most “recent” value and allow “older” values to be overwritten and discarded.
- “recent,” this idea is actually quite misleading
- neither client knew about the other one when it sent its write requests to the database nodes, so it’s not clear which one happened first. we say the writes are concurrent, so their order is undefined.
- Even though the writes don’t have a natural ordering, we can force an arbitrary order on them by assigning a timestamp to each write and pick the biggest time stamp as most “recent”.
- LWW achieves the goal of eventual convergence, but at the cost of durability
- Even if there are several writes to the same key and clients get successful response, only one write will survive and rest will dropped
- only safe way of using a database with LWW is to ensure that a key is only written once and thereafter treated as immutable, thus avoiding any concurrent updates to the same key.
- a recommended way of using Cassandra is to use a UUID as the key, thus giving each write operation a unique key
The “happens-before” relationship and concurrency
- How do we decide whether two operations are concurrent or not?
- two writes are not concurrent when one write a causally dependent on other
- two writes are concurrent: if one client starts the operation and it doesn’t know that other client is also performing the operation on the same key. There is no causal relationship among operations
- that two operations are concurrent if neither happens before the other (i.e., neither knows about the other)
Capturing the happens-before relationship
- the server can determine whether two operations are concurrent by looking at the version numbers
- The server maintains a version number for every key, increments the version number every time that key is written,
- When a client reads a key, the server returns all values that have not been overwritten, as well as the latest version number.
- When a client writes a key, it must include the version number from the prior read, and it must merge together all values that it received in the prior read.
- When the server receives a write with a particular version number, it can overwrite all values with that version number or below
- How do we decide whether two operations are concurrent or not?
CSE138 (Distributed Systems) L3: partial orders, total orders, Lamport clocks, vector clocks
- Happens Before:
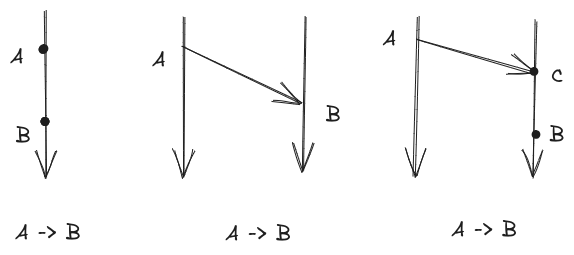 Happens Before relationship
Happens Before relationship- if A and B are 2 events in the same process and A happens before B then A -> B
- if A is a send and B is a corresponding receive then A -> B
- if A -> B and C -> B then A -> B (transitive)
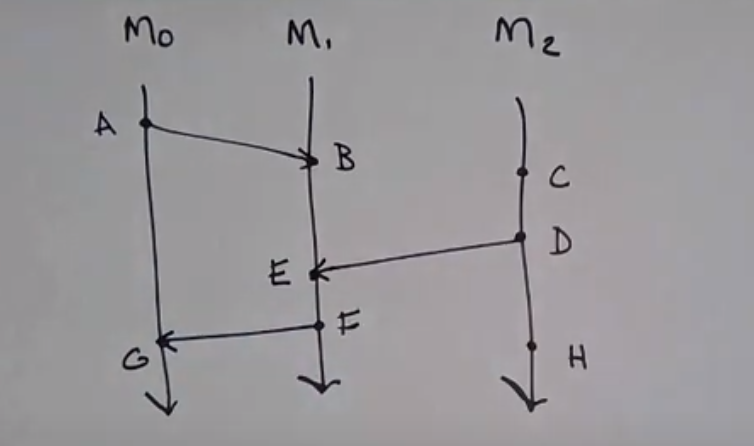
- How are A and E related: A -> B and B -> E so A -> E
- How are D and A related: Not related
- What all places we can go from A ?
- we can go to B,E,F,G but not D
- we say that A and D are concurrent
- What all places we can go from A ?
Partial Order/Partially Ordered Set:
- A set S, together with a binary relation often written as $a \leq b$ (a is related to b this can be the happens before relationship) that lets us compare things in set S and has the following properties
- Reflexivity: $ x \in A, \ a \leq a $
- Anti-symmetry: for all $a, b \in A$ if $a \leq b$ and $b \leq a$ then $a = b$
- Transitivity: $a,b,c \in S$ if $a \leq b$ and $b \leq c$ then $a \leq c$
- We have 8 events ${A, B, C, D, E, F, G, H}$
- We are checking that whether happens before is actually a partial order
- Transitivity is satisfied
- Anti symmetry is vacuously true
- Reflexivity is untrue as $a \leq a$ a happens before a is untrue or doesn’t make sense
- The above shows that happens before is not a partial order or can be said irreflexive partial order
- Example of partial order
- set containment
- the subsets of set of ${a,b,c}$ is a partial order
- ${∅,{a},{b},{c},{a,b},{a,c},{b,c},{a,b,c}}$
- ${a} \leq {a}$ An element is a subset of itself
- ${a,b} \leq {a,b}$ and ${a,b} \geq {a,b}$
- ${a} \subseteq {a,b}$ and ${a,b} \subseteq {a,b,c}$ then ${a} \subseteq {a,c}$
- Elements that are not comparable, for those happens before relation says they are concurrent, those are the elements not ordered by partial order
- In total order every pair of event is ordered
- A set S, together with a binary relation often written as $a \leq b$ (a is related to b this can be the happens before relationship) that lets us compare things in set S and has the following properties
Clocks
- Physical Clocks
- Time of day clocks
- monotonic clocks
- Logical Clocks: Ordering of events
- Lamport clocks
- Assigning number to events
- Denoted as LC(A): Lamport clock of event A
- clock condition: if $a \to b$ then $LC(A) \leq LC(B)$
- Lamport clocks are consistent with causality
- Lamport clock algorithm
- Every process has to keep a counter initialized to 0
- On every event on a process that counter has to increment by 1
- When you send a message, a process needs to include its current counter in the message
- When receiving a message, a process sets its counter to the max(local-counter, received-counter) + 1
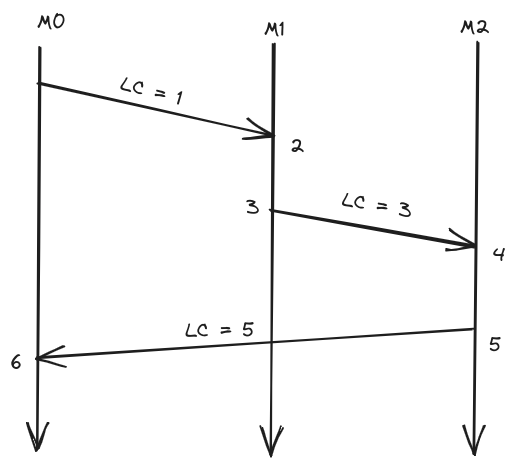 {: width=”700” height=”400” }
{: width=”700” height=”400” }- if $a \to b$ then $LC(A) \leq LC(B)$ but the reverse is not true
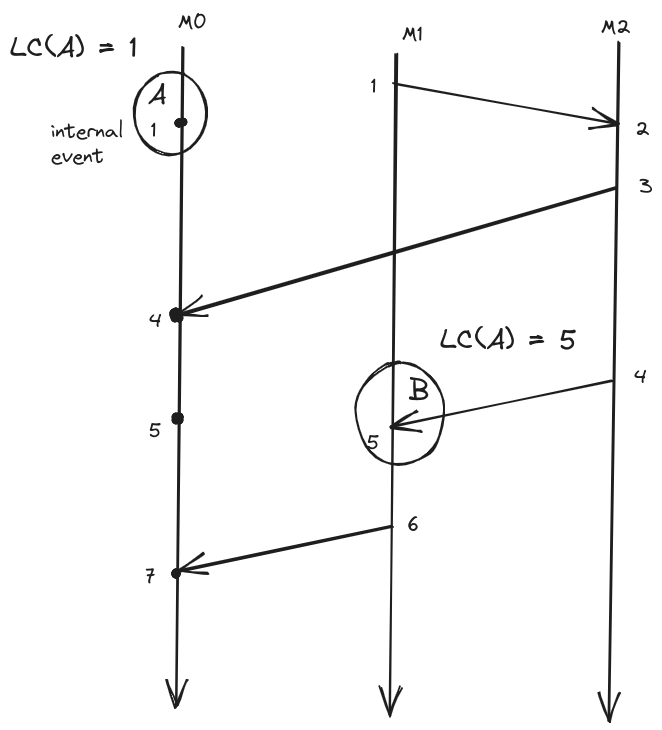
- Lamport clocks are consistent with (potential) causality
- A -> B then logical clock of A < Logical clock of B
- characterizes causality
- if LC(A) < LC(B) then A -> B Lamport clocks do not have this property
- What something we can do with Lamport clocks ?
- what can we do with P -> Q
- we can take its contrapositive
- if P implies Q then
- not Q implies not P or $\neg Q \Rightarrow \neg P$
- $A \rightarrow B \ \Rightarrow \quad LC(A) < LC(B)$
- $\neg \ (LC(A) < LC(B)) \Rightarrow \neg \ (A \to B)$
- We can rule out the possibility that A happens before B
- It might be the case that $ B \rightarrow A \ or \ A \parallel B $
- Lamport clocks can help in ruling out things
- Lamport clocks
Vector Clocks
- $A \rightarrow B \ \Rightarrow LC(A) < LC(B)$ (Lamport clocks)
- LC are “consistent with causality”
- The other direction (“characterizes causality”) doesn’t hold
- Clocks that is consistent with causality and characterizes causality
- $A \rightarrow B \ \Leftrightarrow LC(A) < LC(B)$
- Every process keeps a vector (length N for N processes) of integers initialized to 0 $[0,0,0]$
- On every event, a process increments its own vector clock(all events: sends, receive and internal events)
- when sending a message, a process includes its current vector clock (after the increment from step 2, because sends are events)
- when receiving a message, a process will update its vector clock to the maximum(local,received). local is its own vector clock after incrementing its position, because receives are events
- Max of vectors
- $[1,12,4]$ and $[7,0,2]$ will be $[7,12,4]$ (pointwise maximum)
- Suppose we have a vector clock of $[5,0,0]$ for alice, bob and carol this means alice has seen 5 events whereas bob and carol haven’t seen any
- Physical Clocks
- Happens Before:
CSE138 (Distributed Systems) L4: vector clocks, FIFO/causal/totally-ordered delivery
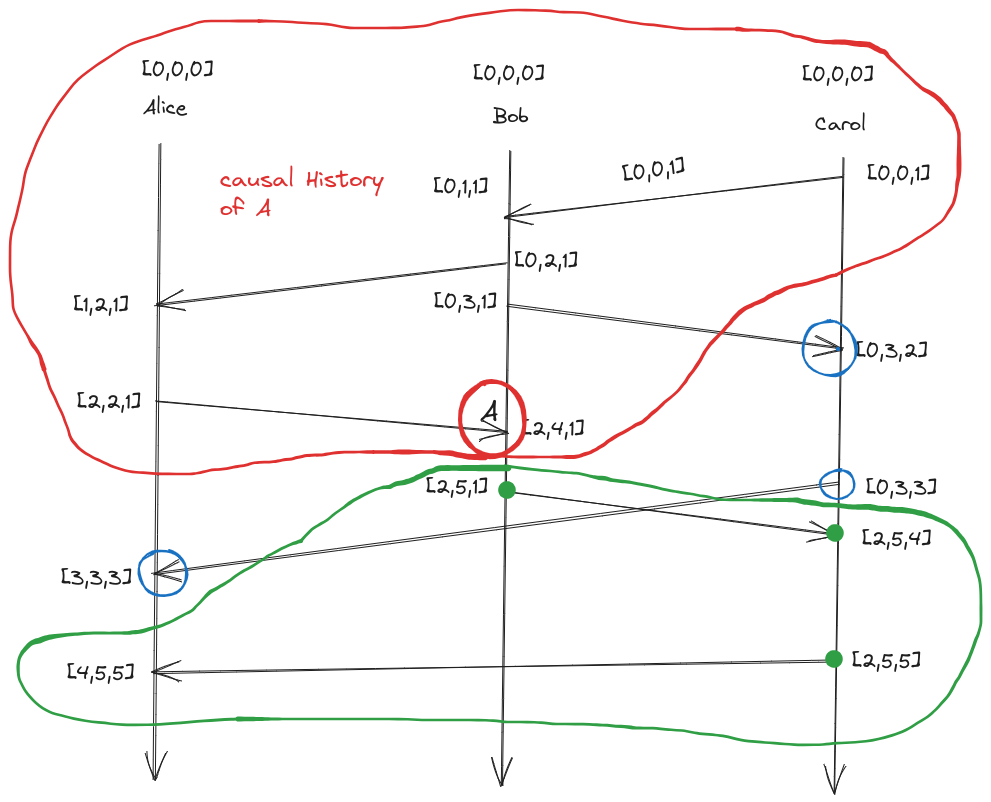
- All the elements in the red circle constitute the causal history of A
- Their vector clocks are smaller than A (the value of elements are smaller in every position)
- The events in the blue circle are the events that are concurrent or causally independent with A
Protocols
- A set of rules that processes use to communicate with each other
correctness property of execution
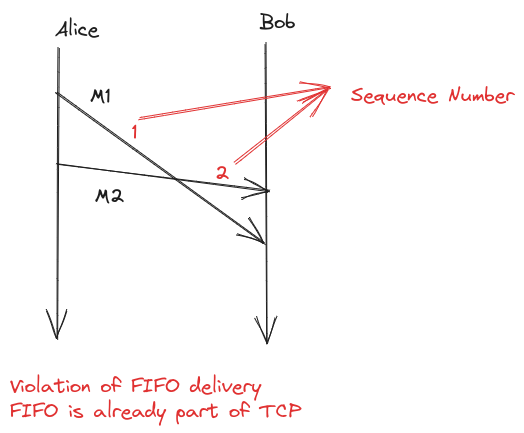
- FIFO Delivery: if a process sends message m2 after m1, any process delivering both delivers m1 first and then m2
- sending a message is something you do
- Receiving a message is something that happens to you
- Delivering a message is something you can do with a message you receive (you queue up a received messages and wait to deliver them)
- Violation of FIFO delivery
- What can we do to implement FIFO delivery
- Sequence numbers: Tag your messages with sender id and sender sequence number
- senders increment there sequence number after sending the message
- if a received message sequence number is the SN of the prev message from that sender + 1, deliver that message
- What will happen if a message doesn’t gets delivered
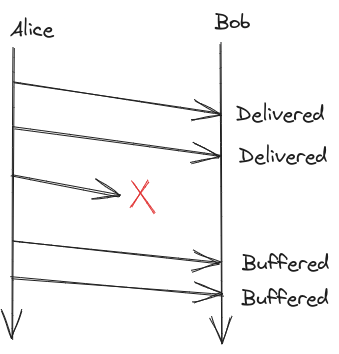
- using sequence numbers only works well if you have reliable delivery
- TCP has reliable delivery
- suppose we don’t have reliable delivery
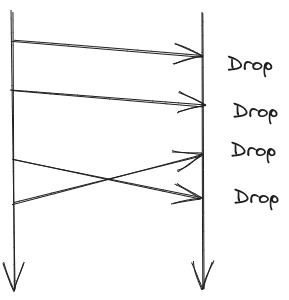
- Vacuously satisfies FIFO delivery
- After every message receive bob can send ack, this also guarantees FIFO delivery but is also slow and ack could also get lost
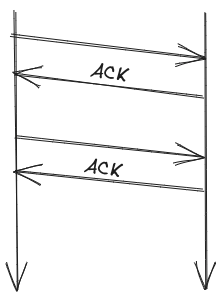
- FIFO Delivery: if a process sends message m2 after m1, any process delivering both delivers m1 first and then m2
Causal Delivery
- if m1 send happened before m2 send then m1’s delivery must happen before m2’s delivery
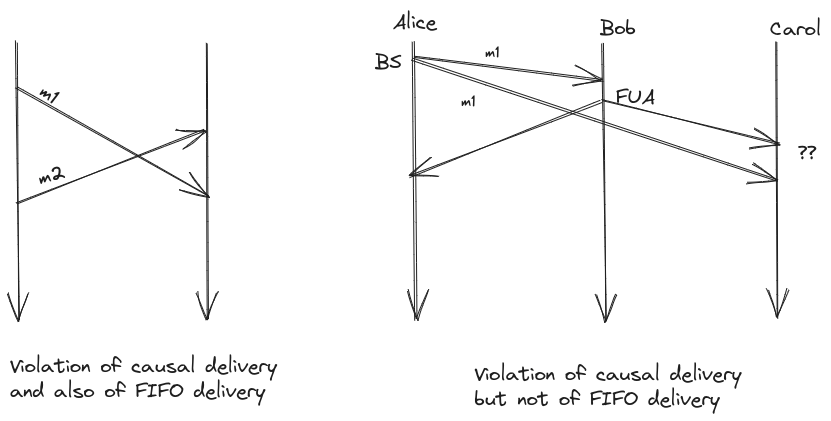
- How to enforce causal delivery? (Hint: Using vector clocks)
- Correctness property of execution
- FIFO delivery
- causal delivery
- Totally ordered delivery
Totally Ordered Delivery
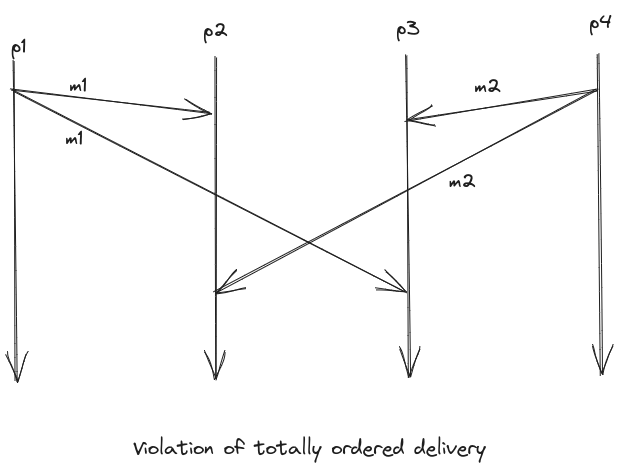
- if a process delivers m1 and then m2, then all processes delivering both m1 and m2 deliver m1 first and then m2
This post is licensed under CC BY 4.0 by the author.